
Article Outline
TOC
Collection Outline
|| scikit-learn
|
- オープンソースの機械学習ライブラリ
- (2007年) Google Summer of Code projectとしてDavid Cournapeau氏によって開発
NumPy、SciPy、matplotlibといったPythonのライブラリ上で動作- 手軽に機械学習の 前処理、 モデリング、 評価指標算出
- アルゴリズムが豊富
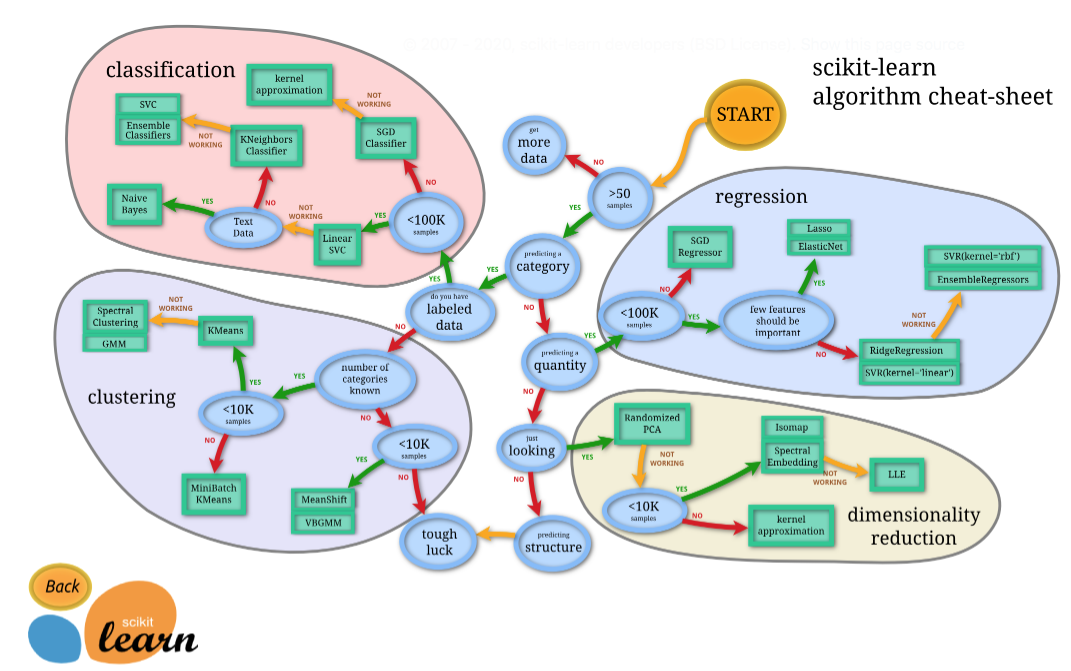
| アルゴリズムチートシート(公式)
|| やってみよう
| 分類予測
import sklearn
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklean.metrics import confusion_matrix
# ALGORITHM
from sklearn import svm
from sklearn.neighbors import KNeighborsClassifier
# DATASET
iris = load_iris()
iris_features = pd.DataFrame(data = iris.data, columns = iris.feature_names)
iris_label = pd.Series(iris.target)
# EDA
# iris_features.head(10)
# iris_features.describe()
# iris_features.isnull().sum()
# iris_label.head()
# iris_label.value_counts()
features_train, features_test, label_train, label_test = train_test_split(iris_features, iris_label, test_size=0.5, random_state=0)
# print('features_train: {}'.format(features_train.shape))
# print('features_test: {}'.format(features_test.shape))
# print('label_train: {}'.format(label_train.shape))
# print('label_test: {}'.format(label_test.shape))
# MODEL
svc = svm.LinearSVC(random_state=0, max_iter=3000)
svc.fit(features_train, label_train)
pred_svc = svc.predict(features_test)
# print(pred_svc)
'''
SVCの予測が上手く振るわない時のモデル群
'''
kn = KNeighborsClassifier(n_neighbors=5)
kn.fit(features_train, label_train)
pred_kn = kn.predict(features_test)
# print(pred_kn)
logleg = LogisticRegression(random_state=0)
logleg.fit(features_train, label_train)
pred_logleg = logleg.predict(features_test)
# print(pred_logleg)
# EVALUATION
print('confusion matrix = \n', confusion_matrix(y_true=label_test, y_pred=pred_svc))
print('accurary =', svc.score(features_test, label_test))
print('confusion matrix = \n', confusion_matrix(y_true=label_test, y_pred=pred_kn))
print('accurary =', kn.score(features_test, label_test))
print('confusion matrix = \n', confusion_matrix(y_true=label_test, y_pred=pred_logleg))
print('accurary =', logleg.score(features_test, label_test))| 回帰予測
import sklearn
import pandas as pd
from sklearn.datasets import load_boston
from sklearn.model_selection import ShuffleSplit
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import train_test_split
# ALGORITHM
from sklearn.linear_model import Lasso
from sklearn.linear_model import Ridge
from sklearn.linear_model import LinearRegression
# DATASET
boston = load_boston()
boston_features = pd.DataFrame(data=boston.data, columns=boston.feature_names)
boston_target = pd.Series(data=boston.target)
# EDA
# boston_features.head()
# boston_features.isnull().sum()
# boston_target.head()
# boston_target.describe()
X_train, X_test, y_train, y_test = train_test_split(boston_features, boston_target, test_size=0.5, random_state=0)
# MODEL
lasso = Lasso(alpha=0.1, random_state=0)
lasso.fit(X_train, y_train)
pred_lasso = lasso.predict(X_test)
ridge = Ridge(alpha=0.5, random_state=0)
ridge.fit(X_train, y_train)
pred_ridge = ridge.predict(X_test)
linreg = LinearRegression()
linreg.fit(X_train, y_train)
pred_linreg = linreg.predict(X_test)
# EVALUATION
print('R-squared : ', lasso.score(X_test, y_test).round(3))
print('R-squared : ', ridge.score(X_test, y_test).round(3))
print('R-squared : ', linreg.score(X_test, y_test).round(3))
cv = ShuffleSplit(n_splits=5, test_size=0.2, random_state=0)
model_list = ['lasso', 'ridge', 'linreg']
for i in model_list:
score = cross_val_score(i, boston_features, boston_target, cv=cv)
print(score)
print('R-squared_Average : {0:.2f}'.format(score.mean()))
print("-"*20)
Cf. 交差検証(cross validation/クロスバリデーション)の種類を整理してみた - AIZINE
