
Article Outline
TOC
Collection Outline
句(節)
演算子
関数
入門 @Udemy
DS100ノック
ML
アクセス解析
|| データサイエンス100本ノック(構造化データ加工編) SQL編
| S-071 ★★
レシート明細テーブル(receipt)の売上日(sales_ymd)に対し、顧客テーブル (customer)の会員申込日(application_date)からの経過月数を計算し、顧客ID (customer_id)、売上日、会員申込日とともに表示せよ。結果は10件表示させれば良い (なお、sales_ymdは数値、application_dateは文字列でデータを保持している点に注意)。1ヶ月未満は切り捨てること。
with tb as (
select
customer_id
, parse_date('%Y%m%d', cast(sales_ymd as string)) as sales_ymd
, parse_date('%Y%m%d', cast(application_date as string)) as application_date
, date_diff(
parse_date('%Y%m%d', cast(sales_ymd as string))
, parse_date('%Y%m%d', cast(application_date as string))
, month
) as month_diff
from
`prj-test3.100knocks.receipt`
join `prj-test3.100knocks.customer` using(customer_id)
)
select *
from tb
where month_diff > 1
limit 10
;| S-072 ★★
レシート明細テーブル(receipt)の売上日(sales_ymd)に対し、顧客テーブル (customer)の会員申込日(application_date)からの経過年数を計算し、顧客ID (customer_id)、売上日、会員申込日とともに表示せよ。結果は10件表示させれば良い (なお、sales_ymdは数値、application_dateは文字列でデータを保持している点に注 意)。1年未満は切り捨てること。
with tb as (
select
customer_id
, parse_date('%Y%m%d', cast(sales_ymd as string)) as sales_ymd
, parse_date('%Y%m%d', cast(application_date as string)) as application_date
, date_diff(
parse_date('%Y%m%d', cast(sales_ymd as string))
, parse_date('%Y%m%d', cast(application_date as string))
, yaer
) as year_diff
from `prj-test3.100knocks.receipt`
join `prj-test3.100knocks.customer`
using(customer_id)
)
select
*
from tb
where year_diff > 1
limit 10
;| S-073 ★★
レシート明細テーブル(receipt)の売上日(sales_ymd)に対し、顧客テーブル (customer)の会員申込日(application_date)からのエポック秒による経過時間を計算し、顧客ID(customer_id)、売上日、会員申込日とともに表示せよ。結果は10件表示さ せれば良い(なお、sales_ymdは数値、application_dateは文字列でデータを保持してい る点に注意)。なお、時間情報は保有していないため各日付は0時0分0秒を表すものとする。
with tb as (
select
customer_id
, sales_ymd
, application_date
, datetime(
-- , format_date('%Y', parse_date('%Y%m%d', cast(sales_ymd as string)))
cast(substr(cast(sales_ymd as string), 1, 4) as int64)
, cast(substr(cast(sales_ymd as string), 5, 2) as int64)
, cast(substr(cast(sales_ymd as string), 7, 2) as int64)
, 0
, 0
, 0
) as sales_ymd_time
, datetime(
cast(substr(cast(application_date as string), 1, 4) as int64)
, cast(substr(cast(application_date as string), 5, 2) as int64)
, cast(substr(cast(application_date as string), 7, 2) as int64)
, 0
, 0
, 0
) as application_date_time
from
`prj-test3.100knocks.receipt`
join `prj-test3.100knocks.customer` using(customer_id)
)
select
customer_id
, sales_ymd
, application_date
, datetime_diff(sales_ymd_time, application_date_time, second)
from tb
limit 10
;
Cf. UNIX時間 - Wikipedia
| S-074 ★★
レシート明細テーブル(receipt)の売上日(sales_ymd)に対し、当該週の月曜日からの経過日数を計算し、売上日、当該週の月曜日付とともに表示せよ。結果は10件表示させれば良い(なお、sales_ymdは数値でデータを保持している点に注意)。
select
customer_id
-- , application_date
, sales_ymd
, date_trunc(parse_date('%Y%m%d', cast(sales_ymd as string)), week(monday)) as sales_ymd_on_monday
, date_diff(
date_trunc(parse_date('%Y%m%d', cast(sales_ymd as string)), week(monday))
, parse_date('%Y%m%d', cast(sales_ymd as string))
, day
) as date_diff
from
`prj-test3.100knocks.receipt`
join `prj-test3.100knocks.customer` using(customer_id)
limit 10
;Cf.[bigquery]対象日付を基準にして、特定曜日の日付を抽出する方法 - 目黒で働く分析担当の作業メモ
| S-075 ★
顧客テーブル(customer)からランダムに1%のデータを抽出し、先頭から10件データを抽出せよ。
with
tb as (
select
row_number() over() as rn
, *
from
`prj-test3.100knocks.customer`
)
, random_tb as (
select
*
from
tb
where
mod(abs(farm_fingerprint(cast(rn as string))), 220) = 0
)
select * from random_tb limit 10
;Cf. BigQuery でランダムサンプリング - medium
%%sql
-- コード例1(シンプルにやるなら)
SELECT * FROM customer WHERE RANDOM() <= 0.01
LIMIT 10※レガシーSQLやPostgreSQL上記のように簡易的にかける。
| S-076 ★★★
顧客テーブル(customer)から性別(gender_cd)の割合に基づきランダムに10%のデータを層化抽出し、性別ごとに件数を集計せよ。
with
tb as (
select
row_number() over() as rn
, *
, count(*) over(partition by gender_cd) as gender_cd_count
, count(*) over() as ttl_count
, (count(*) over(partition by gender_cd)) / (count(*) over()) as gender_ratio
from
`prj-test3.100knocks.customer`
where
gender_cd <> 9
)
/*********************************************
* male=2,981 female=17,918 all=20,899
* male=2,981/20,899 female=17,918/20,899
* male=14 female=86
* male:female=14:86
*
* male=2,981/14 female=17,918/86
* male=212 female=208
*********************************************/
, stratified_sampling_gender_0 as (
select
*
from tb
where
gender_cd = 0
and
mod(abs(farm_fingerprint(cast(rn as string))), 212) = 0
)
, stratified_sampling_gender_1 as (
select
*
from tb
where
gender_cd = 1
and
mod(abs(farm_fingerprint(cast(rn as string))), 208) = 0
)
select * from stratified_sampling_gender_1
union all
select * from stratified_sampling_gender_0
;Cf.
- 16-3. 標本の抽出方法 - 統計WEB
- BigQueryでブートストラップサンプリング - Qiita
| S-077 ★
レシート明細テーブル(receipt)の売上金額(amount)を顧客単位に合計し、合計した売上金額の外れ値を抽出せよ。 ただし、顧客IDが"Z"から始まるのものは非会員を表すため、除外して計算すること。なお、ここでは外れ値を平均から3σ以上離れたものとする。結果は10件表示させれば良い。
with
user_amount as (
select
customer_id
, sum(amount) as amount
from
`prj-test3.100knocks.receipt`
where
customer_id not like 'Z%'
group by
customer_id
)
, statistics as (
select
*
, round(avg(amount) over()) as mean
, round(stddev(amount) over()) as siguma
, round(stddev(amount) over())*3 as siguma_3
from user_amount
)
select
customer_id
, amount
from
user_amount
where
customer_id not in (
select
customer_id
from
statistics
where
amount between (mean-siguma) and (mean+siguma_3)
)
limit 10
;| S-078 ★★
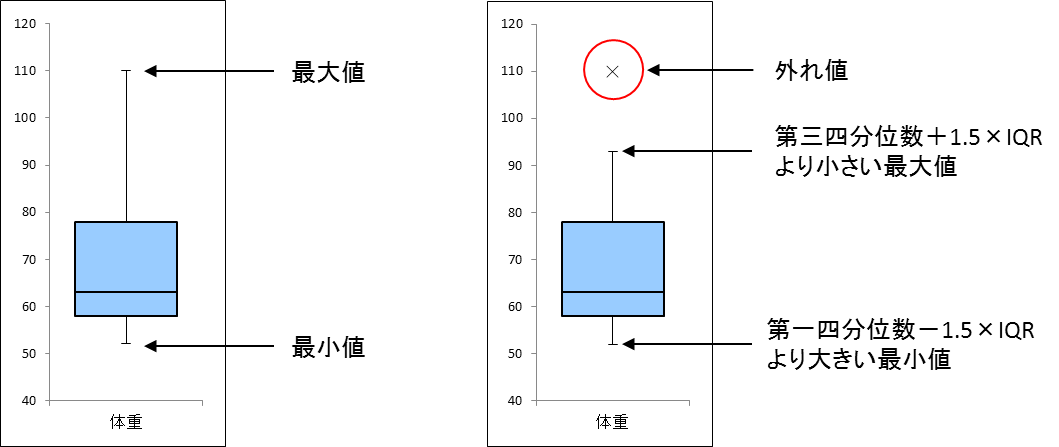
レシート明細テーブル(receipt)の売上金額(amount)を顧客単位に合計し、合計した売上金額の外れ値を抽出せよ。 ただし、顧客IDが"Z"から始まるのものは非会員を表すため、除外して計算すること。 なお、ここでは外れ値を第一四分位と第三四分位の差であるIQRを用いて、「第一四分位数-1.5×IQR」よりも下回るもの、または「第三四分位数+1.5 ×IQR」を超えるものとする。 結果は10件表示させれば良い。
with
user_amount as (
select
customer_id
, sum(amount) as amount
from
`prj-test3.100knocks.receipt`
where
customer_id not like 'Z%'
group by
customer_id
)
, statistics as (
select
*
, round(avg(amount) over()) as mean
, round(stddev(amount) over()) as siguma
, min(amount)over() as min
, percentile_cont(amount, 0.25) over() as q1
, percentile_cont(amount, 0.5) over() as median
, percentile_cont(amount, 0.75) over() as q3
, max(amount)over() as max
, trunc(percentile_cont(amount, 0.75) over() - percentile_cont(amount, 0.25) over()) as IQR
from
user_amount
)
select
customer_id
, amount
from
statistics
where
amount < q1-1.5*IQR
or
amount > q3+1.5*IQR
limit 10
;Cf.
4-3. 外れ値検出のある箱ひげ図 - 統計WEB
| S-079 ★
商品テーブル(product)の各項目に対し、欠損数を確認せよ。
with
col_data as (
select
column_name as key
, data_type
from `prj-test3.100knocks.INFORMATION_SCHEMA.COLUMNS`
where table_name='product'
)
, null_tb as (
select 'product_cd' as key, count(*) as null_ct from `prj-test3.100knocks.product` where product_cd is null
union all
select 'category_major_cd' as key, count(*) as null_ct from `prj-test3.100knocks.product` where category_major_cd is null
union all
select 'category_medium_cd' as key, count(*) as null_ct from `prj-test3.100knocks.product` where category_medium_cd is null
union all
select 'category_small_cd' as key, count(*) as null_ct from `prj-test3.100knocks.product` where category_small_cd is null
union all
select 'unit_price' as key, count(*) as null_ct from `prj-test3.100knocks.product` where unit_price is null
union all
select 'unit_cost' as key, count(*) as null_ct from `prj-test3.100knoks.product` where unit_cost is null
)
select
*
from
col_data
join
null_tb
using(key)
;| S-080 ★
商品テーブル(product)のいずれかの項目に欠損が発生しているレコードを全て削除した新たなproduct_1を作成せよ。なお、削除前後の件数を表示させ、前設問で確認した件数だけ減少していることも確認すること。
with
-- remove null inharit records.
product_1 as (
select
*
from
`prj-test3.100knocks.product`
where
unit_cost is not null
)
select
'削除前' as key
, count(*) as record
from `prj-test3.100knocks.product`
union all
select
'削除後' as key
, count(*) as record
from product_1
;